10/2023 – 03/2024
DriVLMe, Enhancing LLM-based Autonomous Driving Agents with Embodied and Social Experiences
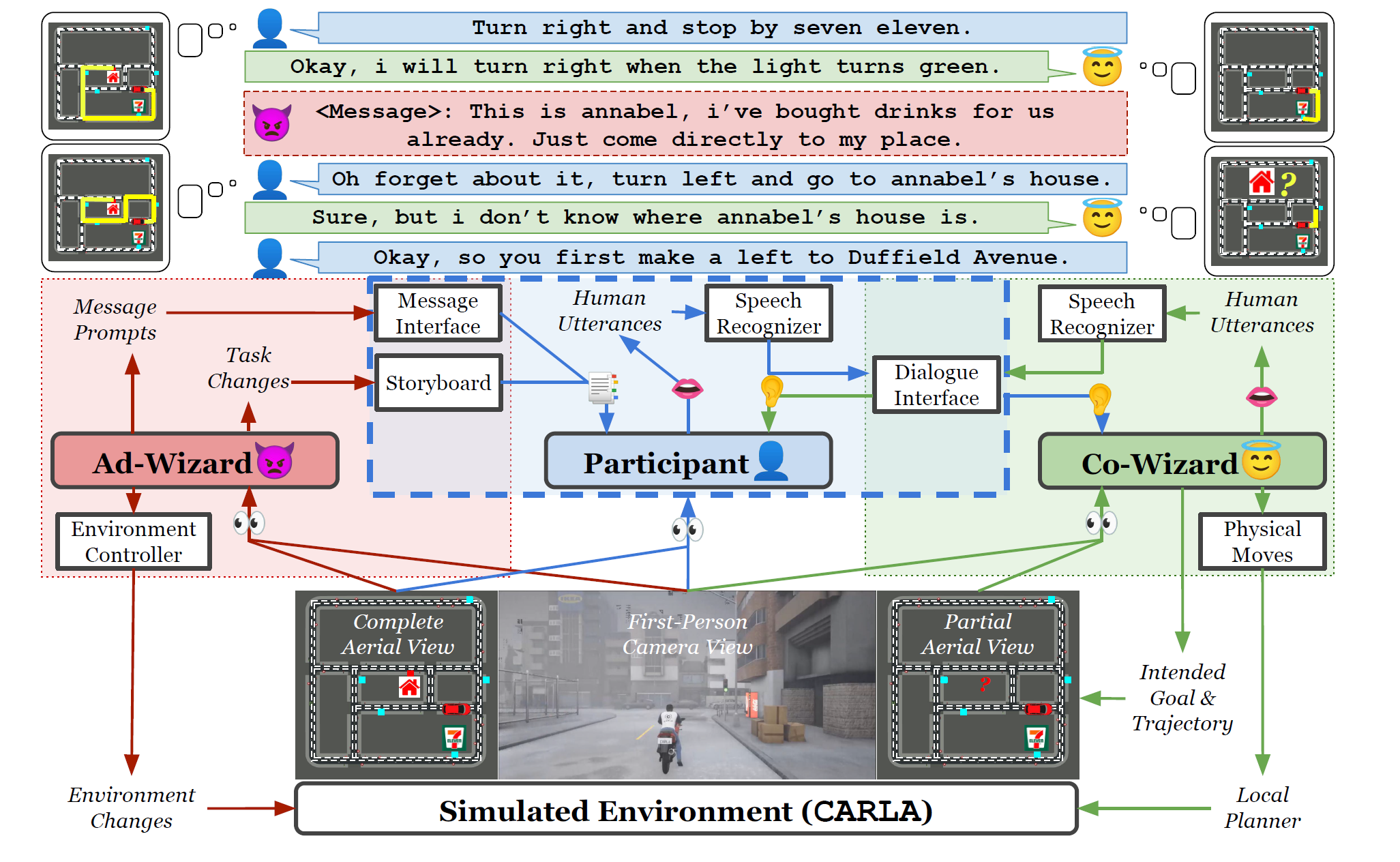
Recent advancements in foundation models (FMs) have unlocked new prospects in autonomous driving, yet the experimental settings of these studies are preliminary, over-simplified, and fail to capture the complexity of real-world driving scenarios in human environments. It remains under-explored whether FM agents can handle long-horizon navigation tasks with free-from dialogue and deal with unexpected situations caused by environmental dynamics or task changes. To explore the capabilities and boundaries of FMs faced with the challenges above, we introduce DriVLMe, a video-language-model-based agent to facilitate natural and effective communication between humans and autonomous vehicles that perceive the environment and navigate. We develop DriVLMe from both embodied experiences in a simulated environment and social experiences from real human dialogue. While DriVLMe demonstrates competitive performance in both open-loop benchmarks and closed-loop human studies, we reveal several limitations and challenges, including unacceptable inference time, imbalanced training data, limited visual understanding, challenges with multi-turn interactions, simplified language generation from robotic experiences, and difficulties in handling on-the-fly unexpected situations like environmental dynamics and task changes.